TV Broadcasting IPTV
Broadcasting equipment
provideoinstruments.com
http://www.305broadcast.com/video-broadcast/tv-encoders-decoders
www.inCOREporation.com
Learn How to Stop Worrying and Build Your Own CDN

This post is adapted from a presentation delivered at nginx.conf 2016 by Jamie Panagos of Charter Communications. You can view a recording of the complete presentation on YouTube.
Table of Contents
| Introduction | |
| 0:25 | CDN Functions |
| 0:50 | IP Video CDN Performance Criteria |
| 1:13 | Why Build Your Own CDN? |
| 1:25 | Commercial CDNs Do a Pretty Darn Good Job |
| 2:00 | The Viewers are Coming |
| 2:26 | What is Driving the Growth? |
| 3:09 | All Content is Not Equal |
| 4:13 | The Impetus |
| 5:16 | Customization Insertion Points |
| 5:52 | The Decision |
| 7:20 | Success Criteria |
| 9:48 | How Might One Build a CDN? |
| 10:37 | Charter Implementation |
| 12:55 | CDN Topology |
| 14:48 | The CDN Stack |
| 16:50 | Why NGINX? |
| 17:56 | Results |
| 19:16 | Moore’s Law Cost Trending |
| 20:10 | What’s Next |
| 22:19 | To Cache or Not to Cache? |
| 24:19 | A Feature-Rich Edge |
| 26:14 | Parting Words |
| Additional Resources |
Introduction
Jamie Panagos: I’m Jamie Panagos. This talk is on why Time Warner Cable, which is now Charter Communications, decided to build our own CDN rather than going with any of the commercial offerings out there, and how we went about building it.
0:25 CDN Functions

I’m sure most of you understand the purposes of a CDN, but I wanted to make clear from Charter’s perspective what we thought a CDN was.
Primarily we want to reduce network traffic. We want to serve clients from the closest cache that is available and allowed to serve that content. If that one goes down, then we want to serve from the next closest one. Pretty simple and straightforward.
00:50 IP Video CDN Performance Criteria

Let’s look at how we measure performance on our CDNs.
We have one simple criteria: average time to serve. We do measure other things. We measure buffering. We measure downshifts. We measure HTTP error codes, but the primary factor that we care about is average time to serve. The lower that number is, the better.
We found that most delivery problems can be traced back to late delivery times.
1:13 Why Build Your Own CDN?

Some of the things we asked ourselves were, “Why do we want to do this? Why do we want to build this ourselves? Why can’t we just go buy something?”
1:25 Commercial CDNs Do a Pretty Darn Good Job

Buying a CDN sometimes makes sense. Commercial CDNs do a pretty good job. They’ve gotten people started in many cases, including us. We wouldn’t be where we are without having commercial CDNs.
This talk is not intended to minimize the value commercial CDNs deliver, but we found that when you have very specialized content that needs lots of customization and lots of care and feeding, it becomes difficult to run a commercial CDN.
For us, we got to that point, and it was a primary driver for why we wanted to do this.
2:00 The Viewers are Coming
For those of us in the video business, a huge reason to create our own CDN was growth. Make no mistake, the viewers are coming. We’re going to see explosive growth on video. We already have, and it’s only going to get bigger.
Most of that traffic is going to be delivered over CDNs in the next few years, so we have to be ready for that.
2:26 What is Driving the Growth?
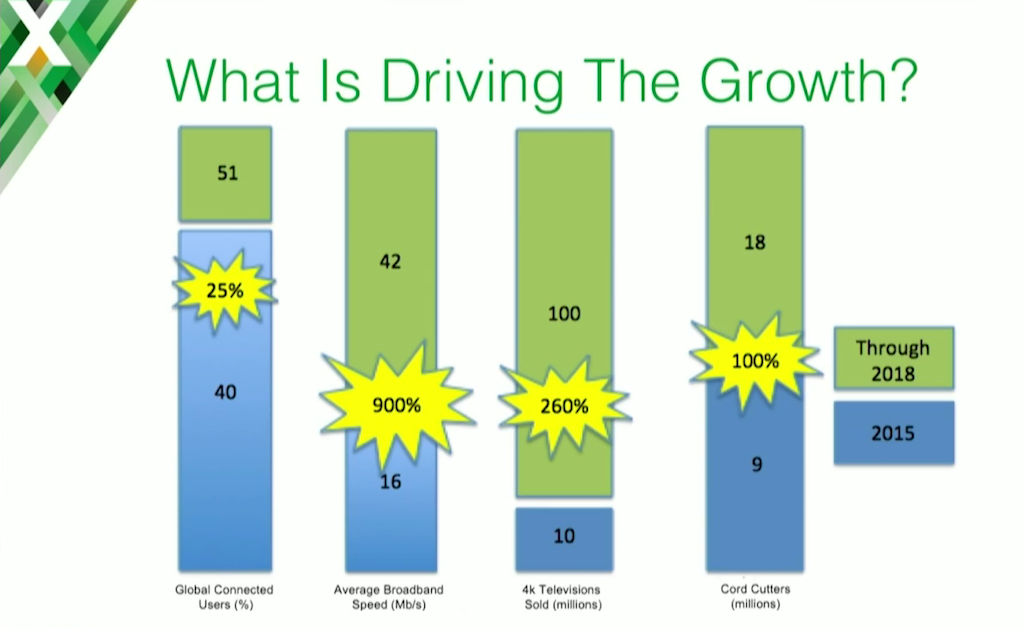
This is some data we found from the Cisco Visual Networking Index.
What we’ve seen is, of that growth shown on the last page, most of it is being driven by average broadband speeds and cord cutters.
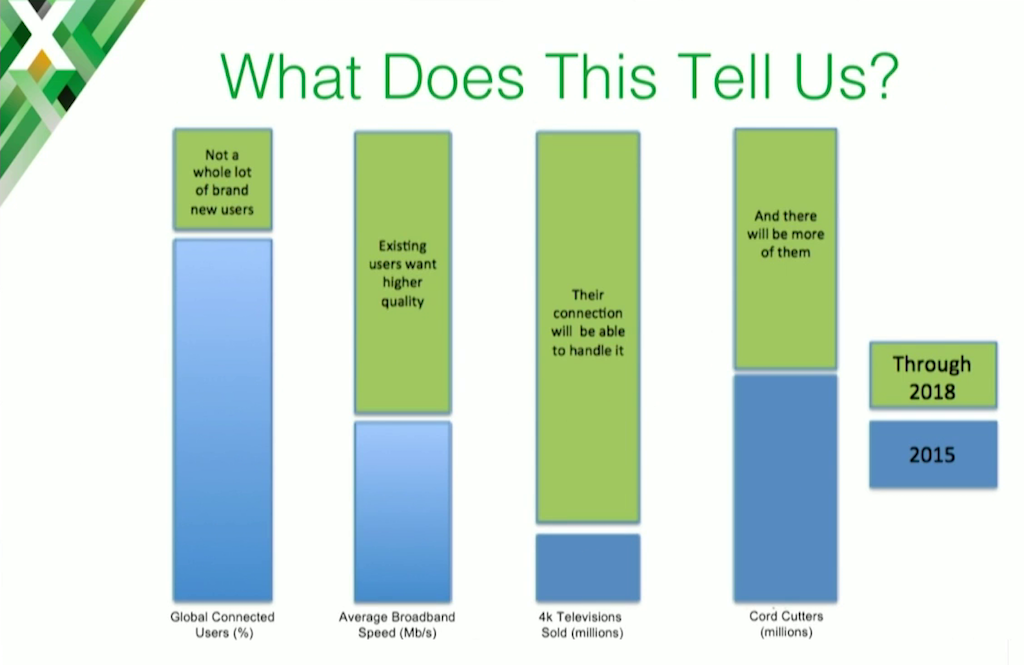
The takeaway from that data is also that people want more content, and they want better content. Also there are many more viewers now and more will come, so we need to be ready.
3:09 All Content is Not Equal

And one of the primary drivers for us after understanding where we needed to go from a statistical perspective is, “What do we need to do to build something to handle a very specialized type of content – adaptive bitrate (ABR) video streaming?”
The primary thing that we needed to understand is that all content is not equal. It’s very different to serve static content – HTML, JavaScript, images – versus ABR video, especially in the live space where that content happens to be very volatile and dynamic. That content is constantly being swapped in and out.
Generalized CDNs, the ones you can buy off the shelf, tend to be built for a relatively small number of relatively large files. They tend to be designed for static content delivery, and they do a very good job of that. If you happen to fall on that category, you can go back to browsing Facebook or whatever you were doing.
If you don’t fall into that category, you may be thinking to yourself, “How am I going to build a new scalable, extensible CDN to handle this traffic going forward?” ABR is perfect example of this type of content.
4:13 The Impetus

We focused on live content initially, because 90% of our traffic happened to be live content. There’s an effort going on for VOD, but that’s a different and potentially slightly easier discussion because it’s less transient data.
We used the commercial CDN that we had been running with for a long time, and we learned a lot of lessons from doing so. I think we helped that vendor as well. As I said, commercial CDNs tend to be generalized CDNs and large file service bureau platforms, which works great until you have a very specialized content type with a different resource profile.
When we scaled the numbers out, the cost of any commercial CDN for delivering high volume of ABR was prohibitive. It was simply cost‑prohibitive. That was reason number one for making our own.
We decided that if we could build it ourselves and we could tailor it for segmented ABR video, we could potentially get better performance, lower cost, better scale, and a lot more control.
5:16 Customization Insertion Points

One of the other ways we came to the decision is: we found that once you start customizing any software enough, at a certain point it becomes more sensible to just build it yourself. You’ve spent so much time customizing it that it becomes impossible for the vendor to support. They can’t do good regression testing on it; it just becomes a really difficult animal to maintain.
This slide illustrates just some of the insertion points that we customized as we went through this process. This is only some of them. As you add more and more of these, it just becomes difficult for a vendor to maintain and to still be the partner that they want to be.
5:52 The Decision

This led us to our decision to build our own ABR video CDN. And there were four major drivers behind that.
The first one was obviously cost. If you can separate yourself from a vendor, you get hardware agnosticism. You don’t have to use certified hardware that the vendor has selected. Now, you can ride the cost‑compression wave of commodity hardware. Software agnosticism means we can use anything we want, including free and open source software. It basically gives us the ability to choose the best tool for the job.
Additionally, we wanted more control. We wanted to separate what a CDN does into different layers. Something like the OSI model. As long as one layer does what the other layer expects, you can use anything you want to get the job done. We wanted to have that sort of modular approach to things and the ability to swap different components in and out.
We also wanted the ability to turn things off. What we found in the commercial CDNs was there are features that we just didn’t care about. There’s multitenancy, there’s logging, there’s all these things that we don’t necessarily care about, but we’re paying for – the systems are using resources to do things that we simply don’t care about.
And then finally, we wanted extensibility. We wanted to be able to grow this in any particular way we wanted. We didn’t want to have to wait in a vendor queue for prioritization, get on the next release cycle, and sometimes even convince them to do it in the first place.
And the last thing, highlighted in the previous slide, at a certain point of customization, you get to a point where you might as well do it yourself.
7:20 Success Criteria

To make sure we ended up where we wanted, we came up with success criteria. We wanted to go back after we deployed this and say, “Did we do this right? Was this something that was worth doing?” We made sure to take operating costs into account as well, it wasn’t just about upfront capital expenditures.
The primary goal was to make sure we were delivering a user experiencer as good as, or better than, [a commercial CDN] at a lower cost point. If we could do that, we felt we had succeeded. In terms of specific performance goals, we wanted to make sure each node could hit 3,000 requests per second. The key parameter was that we wanted to maintain a chunk download time of one second on a cache hit.
Further up the cache backfilling process, we wanted to make sure we stayed under 1.3 seconds. We knew what our tolerance was based on what the client needed to do. The client needs to get the chunk, it needs to decrypt the chunk, it needs to render the chunk, it needs to do any close captioning, all that sort of work. We added that into what we expected the serialization delay to be on the edge and came out with that performance requirement.
We also wanted to make sure the system could scale indefinitely both vertically and horizontally. We wanted to make sure that we didn’t have to do anything to the architecture to make it scale, other than throw more hardware at it.
We also had cost goals. We wanted to make sure we were 50% cheaper at the edge and 75% cheaper at the mid‑tier. Fairly aggressive cost goals. We also wanted to make sure we got double the rack space [compression] with equal capacity.
Finally, for resiliency, we wanted to stay under a second and a half (1500 milliseconds) for our planned failover, and worst‑case failover was below 90 seconds. That sounds like a lot, but in other types of CDNs, DNS trickery specifically, you can see up to 30‑minute failure modes. All of a sudden, 90 seconds doesn’t sound so bad anymore.
The 1500‑millisecond goal was because the premise of the CDN that we’ve built is anycast. Since anycast can shift a little bit depending on what’s going on, we wanted to make sure that if a TCP session was interrupted at any time, it could rebuild and we could get that chunk back before the user would ever even notice.
9:48 How Might One Build a CDN?

That was the why. Now, let’s get into the how.
I want to be clear – this is not a prescriptive technology discussion. This is just saying how we did it. There’s thousands of ways to skin this cat and however you feel like you need to do it is probably good.

CDNs are pretty simple beasts. They’re not necessarily easy, but all they do is direct you to a cache to get content. That’s all they’re doing.
If you can develop a control plane to do that, and develop an operability model with monitoring, alerting, data analysis and trending, and most importantly a console panel for your support center to view the data, you’re pretty damn close to a CDN.
10:37 Charter Implementation

The first thing we did was ask ourselves, “Do we really need a control plane?” A control plane is another part to break. It’s another thing to monitor, and it’s something that can potentially add latency to your solution. So we asked ourselves, “Do we even need one?” And we came up with a design that said no, we don’t need one.
In our design, CDN nodes are actually completely autonomous. There’s no centralized control plane. There’s no centralized brain. All the nodes act on their own behalf. The system leverages the IP network itself for closest cache selection. The role that a centralized control plane would usually play – deciding, “You’re in New York, so I’m going to give you a New York cache” – is entirely done by the network itself.
The reason for that is, generally speaking, IP networks prefer to get packets off their network as fast as possible. That’s their entire goal. So we said, “Hey, what if we start participating in the network domain and let the network decide where to forward packets, rather than having us making that decision?”
In addition to that, there’s a health check, and the health check monitors the system for a bunch of things. It monitors for CPU utilization, memory utilization, NIC utilization; it asks “Can I pull content for myself? Are the directories that I expect to be there actually there? Do they have the right permissions?” It checks a whole laundry list of things, and it spits out a score.
Based on that score, the node attracts the appropriate amount of traffic, utilizing the IP network. The result is a self‑leveling system. If systems get too overutilized, they start repelling traffic and pushing that traffic to the next closest cache. Eventually, you get to a scenario where the whole system is self‑leveling.
The other important thing we did was: as we built the system – from architectural design all the way through operational deployment – the monitoring and management of the system was built in lockstep. It wasn’t an afterthought. We didn’t get to the end and say, “Man, we really need to operate this thing. We really need to monitor this thing.” That was an architectural decision up front. And as a result by the time we went to market with it, it was a well‑tested, full‑featured system that we could basically hand over to our support center, and they were ready to go.
Finally, anycast is OK in TCP environments. I know that’s a scary sentence for some people, but I promise it’s OK, in some situations.
12:55 CDN Topology

Our topology is a bunch of edge nodes spread out across the country.
The red nodes are national data centers. The edge nodes pull from those based on proximity. Like I said, the CDN nodes participate in the routing domain, and they use BGP to do that. There’s no hard requirement for that. We could use other routing protocols, but BGP is probably the safest one to use.
Services are bound to some number of IP[v4] or IPv6 addresses. CNN is a good example, or Fox, might be bound to a list of IP addresses. The host names that the clients receive resolve to those IP addresses. If you do a DNS lookup on the CNN hostname, it’ll resolve to a certain number of IP addresses.
Based on that, statistically speaking, each one of those IP addresses is carrying a certain amount of traffic. If there are 20 IP addresses, each one of them is carrying 1/20th of the traffic. This is important for how we do our traffic shedding. The nodes that are allowed to advertise, let’s say, CNN content use BGP to advertise the routes associated with CNN.
So this is how we’re attracting content. If a node can service CNN requests, it advertises the CNN routes. If it can’t, it doesn’t, and users are forced to go elsewhere for that content.
Because there’s a certain number of nodes (let’s say 20), if a node becomes overwhelmed, it can start shedding some percentage of those routes (let’s say 5). And if it sheds 5 of those routes, 25% of the traffic has to go elsewhere. So, that’s how we end up with this self‑leveling system.
Backfilling works the exact same way. It’s a different set of IP addresses, but when the edge nodes need to backfill from a mid‑tier, they use the same exact logic. This tiers [scales] almost indefinitely.
14:48 The CDN Stack

This is our stack. As I mentioned before, we took a long, hard look and decided that a layering strategy was good, since it lets us modularize and pull out and put in parts interchangeably.
Everything in the gray box is on a single node, and then there are other pieces surrounding it that are either its clients, or are operational pieces. The caching daemon actually happens to be NGINX, in a strange turn of events.
We’re using BIRD as a routing daemon. That’s the piece that’s actually running BGP with the IP network. We’re running CentOS as our base OS, and that’s all driven with Puppet so we don’t really touch those boxes too much manually.
And then we have some stuff on the right for data analysis, trending, alerting, and putting data in front of our support center. And then on the top, you have the two clients up there, the people who are actually watching the Muppets.
The nice part about this is that we can pull out pieces and put in pieces independently. If we decide, “Hey, you know, BSD might be a little bit better for networking”, we can pull out CentOS, put in BSD, and nothing else really changes. We really wanted to take that approach because we might find that for certain types of traffic, certain things work better.
The other piece that we have in here is the homegrown health tracker. This is the only thing that we had to build to make our architecture work. This is what I was talking about before that monitors the system for its own health, and it instructs BIRD what it needs to do. Does it need to withdraw routes? Does it need to advertise routes? Does it need to pull all its routes out entirely because it’s in a really, really bad state, or because somebody’s instructed it to go into maintenance mode?
An important thing to mention is, the homegrown health tracker exposes an API, which is how we do everything. All of the command and the control is done through an API. Things can be automated, our support center has a live view of things, and that’s all done through that API.
16:50 Why NGINX?

Why NGINX? We started with a laundry list of caching daemons. You can probably guess which ones they were. Some failed the initial performance requirements. I’ve already mentioned our requirements for failover, delivery time, and the number of client requests, and some of [the candidates] just failed off of those criteria. The criteria themselves narrowed down the numbers. We also had some requirements for the footprint of the daemon, so we couldn’t use more than a certain amount of RAM and other limited resources. Other caching daemons failed there as well.
We got down to a couple, and that’s where the driving factor really became operability – how easy was this going to be to use in practice? We did some test cases with people to see how they could operate and monitor the situation. We found that NGINX far and away was the easiest daemon to operate. You can read an NGINX config and it makes sense to you. That doesn’t mean we couldn’t use another cache daemon, but with everything else equal, the deciding factor was “How easy is this thing going to be to operate?”
And that’s why we went with NGINX.
17:56 Results

These are some empirical results we ended up getting. We hit 350 Gbps of live content during the Olympics. That’s live television. We got down to about 450 milliseconds for average serve time for our largest HLS chunks. Each is a 6‑second [long], 3.4 MB chunk.
We eliminated the control plane entirely, so that cost went down 100%. We reduced our edge node cost by 60%, and our goal was 50%, so we hit that. We got exactly our goal for mid‑tier node cost reduction, 75%.
OPEX costs were mostly in the initial development of the homegrown health checker, and then partly in the ongoing care and feeding of the system. These costs fell pretty much in line with what we were paying our commercial CDN operator to do support for us. So, OPEX was kind of a net.
The final one that I’m really happy with and proud of is that we’ve reached 33% IPv6 penetration on IPv6‑enabled devices. We expect that number to grow with the more people actually supporting IPv6. That was an important goal of ours initially, to make sure we were IPv6 out of the box.
19:16 Moore’s Law Cost Trending
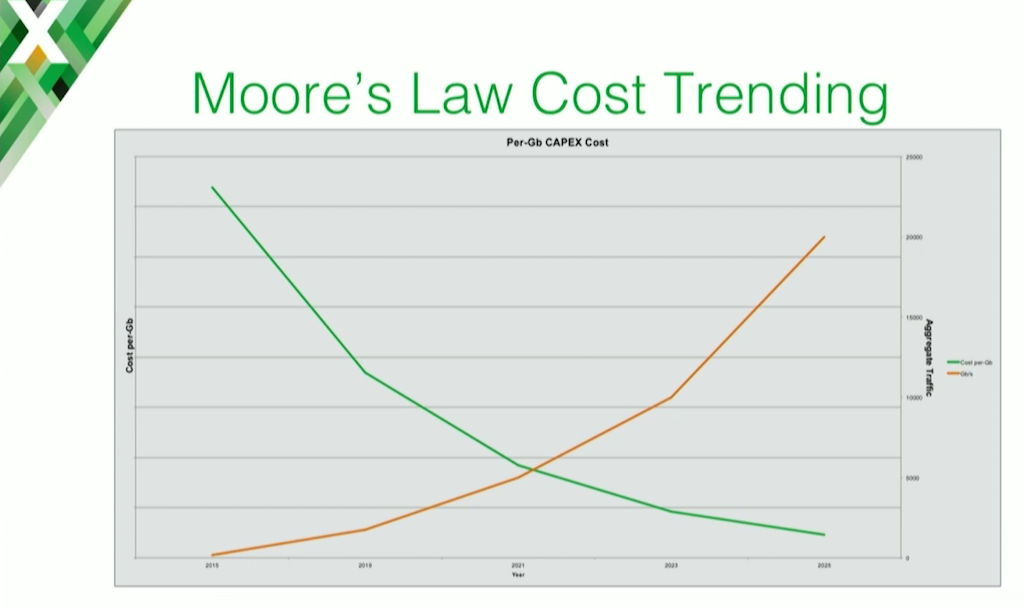
We also wanted to see how this scales going forward. This is important, because our projections put us in the tens of terabits (TB) over the next few years, and obviously cost is going to be an important part of that.
Just using Moore’s Law and nothing else – not taking into account if we can get more performance out of using a different OS or tweaking some TCP parameters, or using HTTP 2.0, stuff like that – it puts us at about 20 TB. We fall under $500 per Gbps, which scales much better than anything else we found out there. This is just purely riding the cost‑compression wave of Moore’s Law.
20:10 What’s Next

That’s where we are today. I like to say that we’re in the base model right now. It’s running, serving traffic, BGP is doing its thing; but we want to be smarter about this as we go along, and want to get better at doing this everyday.
We have some ideas on how we get there. Primarily, we want to get smarter about when to cache, and where to cache. So basically we’re trying to be more efficient. That’s the way we’re going to be able to scale to the numbers we need to. Backfilling is expensive. I’ll talk about that a little bit more in a minute.
We want to add features, but we want to do so carefully. One of the primary principles at Charter is “keep things simple”. There’s always a cost‑benefit analysis done on any features we want to push out. We want to keep the CDN a fat, dumb pipe. Moving bits, that’s all it should be doing. If there’s something else that’s going to be put into that call flow, it needs to be very much worthwhile.
We want to build on existing protocols to create a more robust distributed control plane. We’re very likely to start leveraging BGP even more to communicate state information about the CDN, content availability on the CDN, and failover within the CDN.
Finally, now that we’ve got this up and running, we’re spending a lot of time to collect the data (all the sys logs, all the client data coming off the clients, and a host of other data), and putting that into big‑data analytics to come up with algorithms that can help us predict failure. We’re seeing that failure signatures tend to look the same. We want to see and understand when it looks like failures are about to happen so we can get ahead of it, rather than waiting for them to happen and have customers impacted before addressing them.
The other thing we’re doing is looking for ways to respond to those signatures quickly. If we know the fix for a CDN node having issues is to shut down BGP, why wait? Why wait for customers to be impacted, why wait for somebody to get on the phone, do an escalation, all those things that need to happen before BGP shut down in the normal flow, when in a second or two we can go and shut down BGP on our end? We want to start thinking about how to get in front of issues like that.
22:19 To Cache or Not to Cache?

The question with CDNs ends up being one of the two difficult computing questions: when to cache or not to cache, and when to evict. Those are the big problems. But the better you can do that, the better efficiency you get.
The first step is pretty easy, and NGINX actually offers us a feature to do that, which is the
proxy_cache_min_uses directive. If something isn’t going to be requested that frequently, don’t bother caching it. That’s a pretty simple one. But then we need to get more complicated because we want to get the efficiency even higher.
The second step is to start scoping content based on anticipated popularity. For instance, based on some predictor, if we don’t think a piece of content is going to be very popular, instead of caching it, we either serve it without caching it, or potentially punt it over to another server whose job is to cache long‑tail content.
Then the caches that are serving your CNNs, your Foxes, all the really popular stuff, can focus on that content. The root problem is that a chunk of unpopular [content] takes up just as much space as a chunk of popular. We want to protect that very valuable cache resource. By understanding what things are likely to get hit again, you can bump up cache efficiency. That’s a huge optimizer for us.
And then finally, we’re going to be looking into doing some predictive cache filling. The nice part about live content is the chunk‑naming mechanism is basically serial. If a client has requested chunk 1, the next one’s going to be chunk 2. Based on an understanding of what’s going to be popular, and the likelihood that the next chunk is going to be requested, you can get in front of that and do some predictive cache filling, saying, “If you’ve requested the first chunk for CNN, you’re probably going to request the second one”.
The whole goal with this is to prevent the first‑request penalty for a customer. The first customer requesting something has to [wait as the request goes] all the way back, potentially to the origin server.
If we can get ahead of that, we save that customer that penalty. That’s big for us.
If we can get ahead of that, we save that customer that penalty. That’s big for us.
24:19 A Feature‑Rich Edge

We want to keep the edge simple, but having control of the full stack does allow us to consider some wacky ideas.
As I mentioned, putting anything in the forwarding path will always slow things down. You always have to do the cost‑benefit analysis. However, caching isn’t a CPU‑intensive function, so we do have some cycles lying idle. In a lot of cases, a lot of your CPU cores are just there because you need more memory. So they’re actually not really there for any particular CPU‑based reason.
One of the things we’re considering doing is some packaging at the edge. Taking a DASH‑like media file format and turning it into HLS, or SmoothStream, or whatever happens to be at the edge. That way, we can cache the base content and get a lot more efficient there. Also encoding at the edge, so taking a raw TS feed and doing your encoding there.
We’re also thinking about doing multicast‑to‑ABR translation at the edge or vice versa. This is because today, we carry both an ABR version of the content and a multicast version of the content for regular set‑top boxes across the backbone. Maybe we don’t have to do that. Maybe we can only carry one and do a translation at the edge to the other, saving ourselves half of the capacity on the network.
And then finally, manifest manipulation at the edge is to support things like advertisements and blackouts. If we can get smart about doing manifest manipulation at the edge, we get two benefits: we get a dramatic scaling benefit, because every time you put in a new edge node, you’ve now increased your manifest manipulation capacity, and you’re putting the manifest manipulation as close to the user as possible.
Those are just some of the wacky ideas we’re considering.
26:14 Parting Words

Like I said before, this talk was not meant to be prescriptive. The idea is for you to come up with a design that meets your needs.
The main idea is, building your own CDN isn’t impossible or even that scary. It’s possible and it’s something you can do if needed.
Editor – For those of you who aren’t film buffs like Mr. Panagos, the title of his talk is inspired by the 1964 film Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb, directed by Stanley Kubrick and #26 on the American Film Institute’s list of the 100 Greatest American Movies of All Time.
The image above is from the final moments of the film and is the property of Columbia Pictures Corporation.
Additional Resources
Editor – For more information about using NGINX and NGINX Plus as a CDN cache and generalized web cache, check out these related resources:
- A Guide to Caching with NGINX and NGINX Plus
- Streaming Media Delivery with NGINX Plus
- Smart and Efficient Byte‑Range Caching with NGINX & NGINX Plus
- The Benefits of Microcaching with NGINX
- Shared Caches with NGINX Plus Cache Clusters, Part 1
- Shared Caches with NGINX Plus Cache Clusters, Part 2
- NGINX Content Caching (NGINX Plus Admin Guide)
- Content Caching with NGINX Plus (webinar)
- Globo.com’s Live Video Platform for FIFA World Cup 2014, Part 1: Streaming Media and Caching
- Why Netflix Chose NGINX as the Heart of Its CDN
To try NGINX Plus, start your free 30-day trial today or contact us to discuss your use cases.


